
Запуск и использование Subgraph Vega на Debian 11
Vega — довольно древний автоматизированный сканер уязвимостей для сайтов. Он все еще используется некоторыми пентестерами и мамкиными хакерами с Kali Linux. Сканер идеален для базовой проверки кастомного говнокода. Также поддерживается авторизация различными способами (Basic HTTP, Digest HTTP, NTLM, макросы, кукисы), что позволяет проверить закрытые части сайта типа админок и личных кабинетов.
Vega доступна не только для Linux, но и для MacOS и Windows.
Перед запуском указывается адрес сайта, параметры сканирования, и запускается сканер. После окончания получаем отчет о возможных уязвимостях, отсортированных по важности:
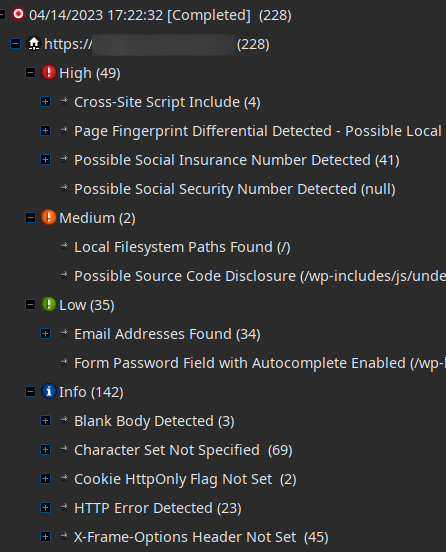
По каждой проблеме можно глянуть подробную инфу и с чем это едят.
Установка
Сам сканер распространяется в виде архива с бинарником с официального сайта, а также доступна dev версия на гитхабе в виде исходников для сборки. Dev версия тоже древняя, но есть какие-то багфиксы + экспорт отчетов в html (кстати, у меня экспорт не работает).
Официальная стабильная версия
Скачиваем к себе в любое место архив с офсайта:
wget https://support.subgraph.com/downloads/VegaBuild-linux.gtk.x86_64.zip
распаковываем:
unzip VegaBuild-linux.gtk.x86_64.zip
Архив распакуется в директирию vega в директорию с архивом.
Dev версия с Github
У официальной dev версии есть проблемы со сборкой, но нашел ее форк с фиксами и headless режимом на python. Форк собирается без проблем на Debian 11.
Для сборки потребуется ant. Сразу устанавливаем его:
sudo apt install ant
Клонируем репозиторий:
https://github.com/anneborcherding/Vega
Переходим в директорию с исходниками:
cd Vega
И запускаем сборку:
ant
После окончания сборки увидим сообщение:

Готовый архив будет лежать в build/stage/I.VegaBuild/VegaBuild-linux.gtk.x86_64.zip.
Для запуска в headless режиме нам еще будут нужны некоторые зависимости. Устанавливаем их:
apt install python3 xvfb
pip3 install py4j
Запуск
Vega работает на виртуальной машине Java 8 и использует устаревшую либу libwebkitgtk-1.0, которых для Debian 11 конечно же уже нет. На офсайте Oracle на момент написания поста можно скачать только 11 и 17 версии. Java 8 и libwebkitgtk-1.0 еще есть в репозиториях Debian 9. Репозиторий можно не подключать, нам нужно всего несколько пакетов.
Скачиваем и устанавливаем Java 8 (openjdk-8-jre-headless):
wget http://security.debian.org/debian-security/pool/updates/main/o/openjdk-8/openjdk-8-jre-headless_8u332-ga-1~deb9u1_amd64.deb
sudo dpkg -i openjdk-8-jre-headless_8u332-ga-1~deb9u1_amd64.deb
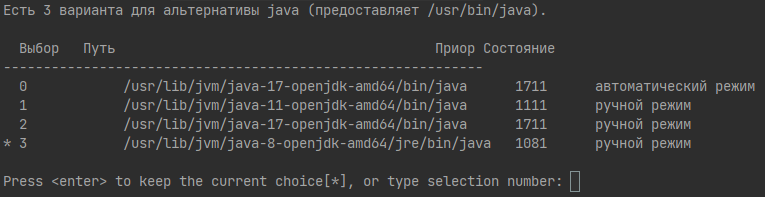
Если стоят какие-то еще версии, то делаем 8 версию дефолтной:
sudo update-alternatives --config java
Здесь выбираем нужную версию цифрой и жмем enter:
Теперь скачиваем libwebkitgtk-1.0 с зависимостями и устанавливаем:
wget http://ftp.debian.org/debian/pool/main/w/webkitgtk/libwebkitgtk-1.0-0_2.4.11-3_amd64.deb
wget http://ftp.debian.org/debian/pool/main/w/webkitgtk/libjavascriptcoregtk-1.0-0_2.4.11-3_amd64.deb
wget http://security.debian.org/debian-security/pool/updates/main/i/icu/libicu57_57.1-6+deb9u5_amd64.deb
sudo dpkg -i libicu57_57.1-6+deb9u5_amd64.deb
sudo dpkg -i libjavascriptcoregtk-1.0-0_2.4.11-3_amd64.deb
sudo dpkg -i libwebkitgtk-1.0-0_2.4.11-3_amd64.deb
sudo apt-get install -f
Теперь можно запустить кликом по бинарнику либо через терминал:
./Vega
При желании можно создать ярлык для запуска. Перед этим желательно сразу переместить куда-нибудь в системные директории:
sudo mv vega /opt/
После этого создадим ярлык /usr/share/applications/Vega.desktop примерно с таким содержимым:
[Desktop Entry]
Name=Vega
Exec=/opt/vega/Vega
Icon=/opt/vega/Vega.png
Terminal=false
Type=Application
Теперь можете запускать сканер из меню приложений.
Если все сделали верно, то увидим главное окно программы:
Использование
Приведу пару простых примеров использования: простой скан сайта, скан закрытых частей сайта на WordPress и headless режим.
Простой скан сайта
Тыкаем на значок с плюсиком в верхней панели:
Вводим урл сайта (полный с протоколом) и жмем Next:
Выбираем модули (можно выбрать все) и жмем Finish:
Теперь ждем окончания сканирования. Сканер будет делать множество http запросов. Поэтому заранее нужно вырубить всякие блокировки от большого кол-ва запросов. И смотрим, чтобы ваш хостинг/сервер не падал при сканировании тормозных сайтов. Желательно вообще запускать сканер локально.
В процессе сканирования уже можно смотреть в левой панели, какие проблемы он нашел.
Сканирование WordPress с авторизацией
В WordPress авторизация работает на кукисах. По идее это должно упростить авторизацию, но у меня так и не получилось авторизироваться куками через Vega. Для авторизации будем использовать макросы. Для создания макроса нужно будет записать реальную авторизацию через встроенный прокси сканера, а потом уже использовать этот макрос при сканировании. Единственный минус — сайт должен работать по http.
Переходим во вкладку Proxy:
Запускаем прокси:
В браузере (в моем случае Firefox) настраиваем подключение через прокси сканера:
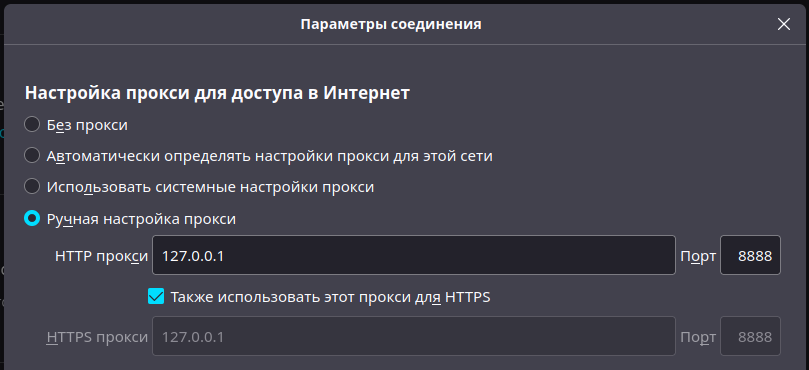
Если браузер правильно работает через прокси, то при переходе по страницам увидим все запросы в окне Vega.
P.S. некоторые браузеры игнорируют настройки прокси. В этом случае прокси надо цеплять в настройках сети ОС.
Авторизуемся в админку через wp-login.php и ищем POST запрос авторизации (там как раз можно увидеть установку авторизационных кукисов):
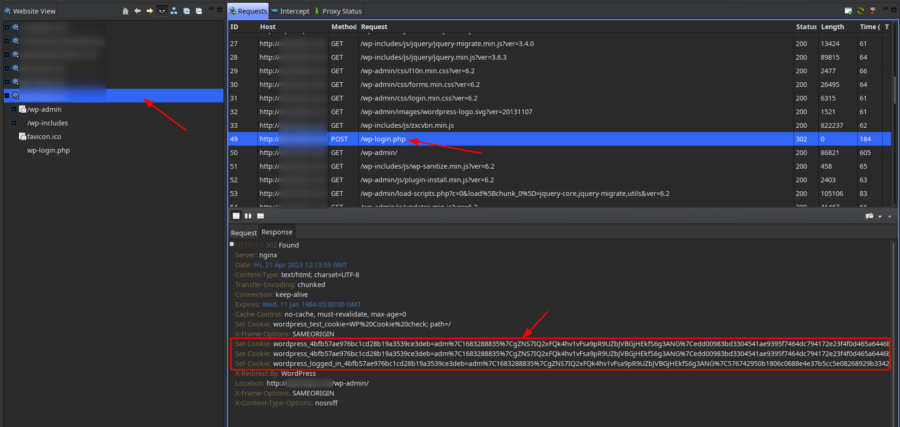
Теперь прокси можно отключить в Vega.
Переходим во вкладку Scanner и в нижнем окне добавляем учетку авторизации:

В открывшемся окне вводим любое название и тип macro:
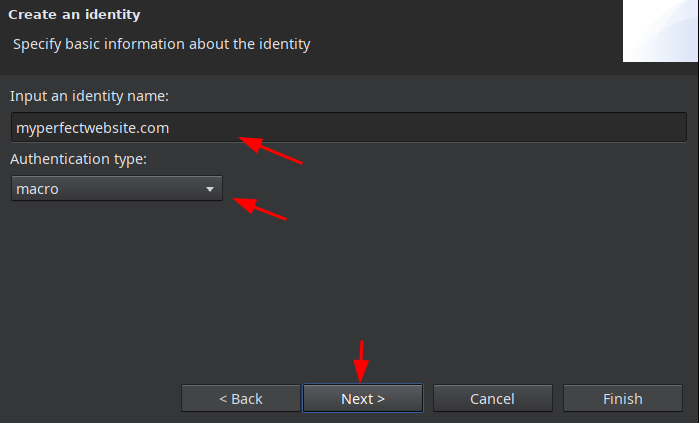
В следующем окне создаем макрос:
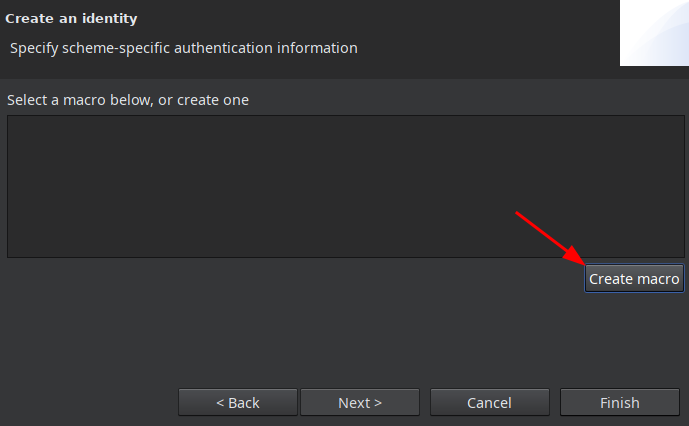
Вводим любое название и жмем кнопку add item:
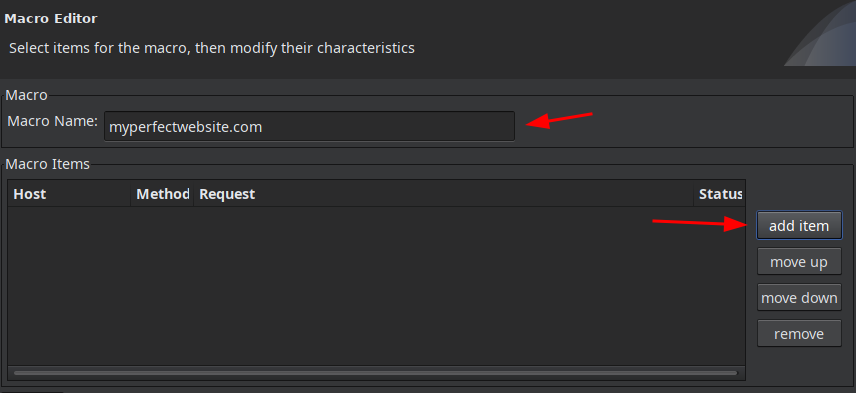
В открывшемся окошке выбираем наш POST к wp-login.php запрос и жмем кнопку OK:
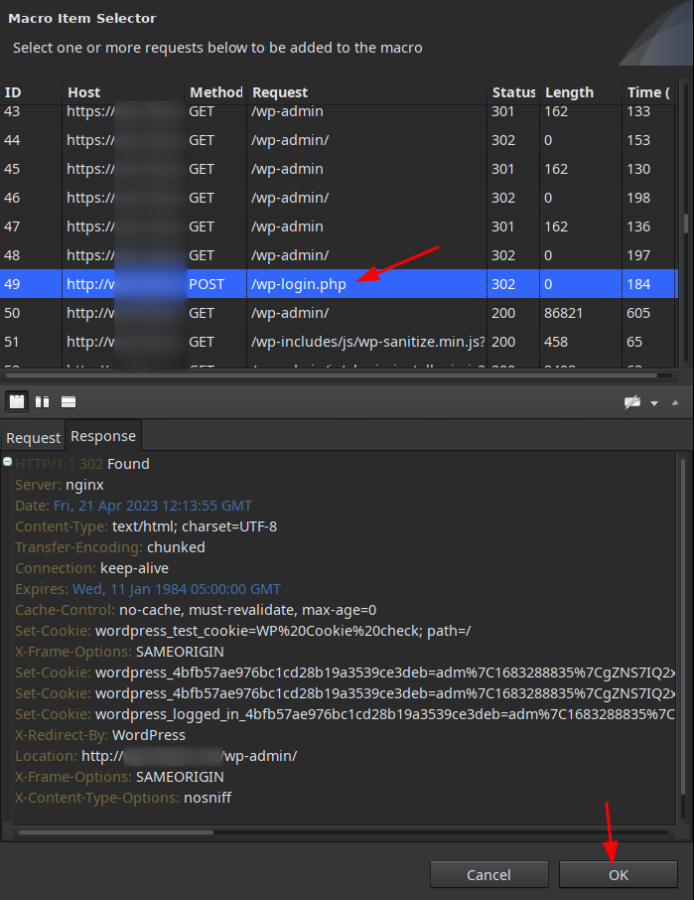
Далее жмем OK:
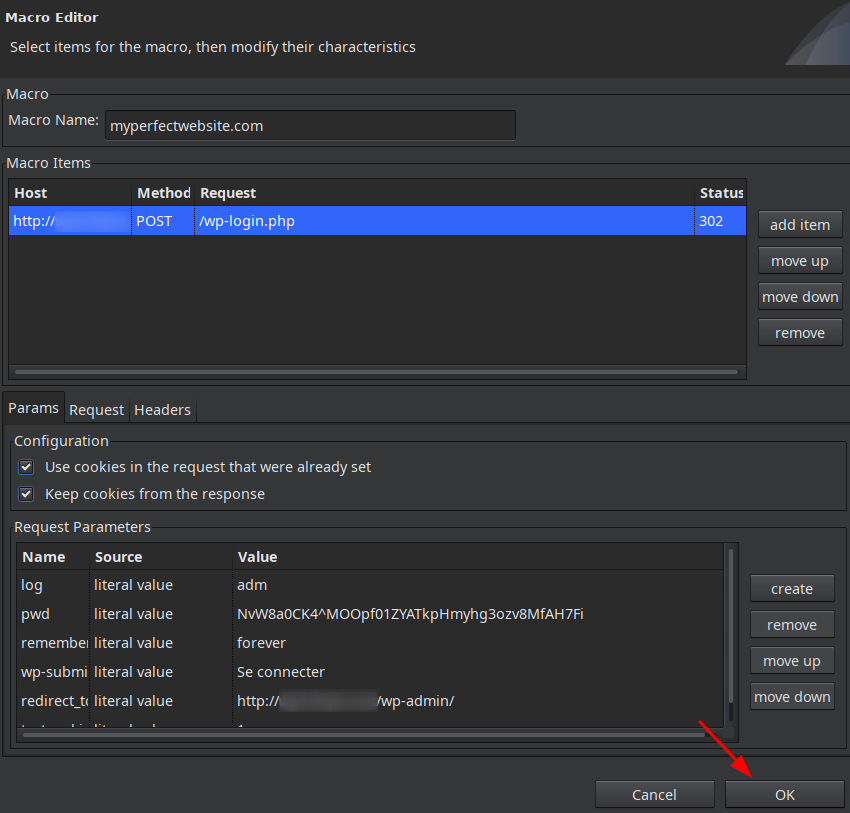
И в следующем окне жмем Finish:
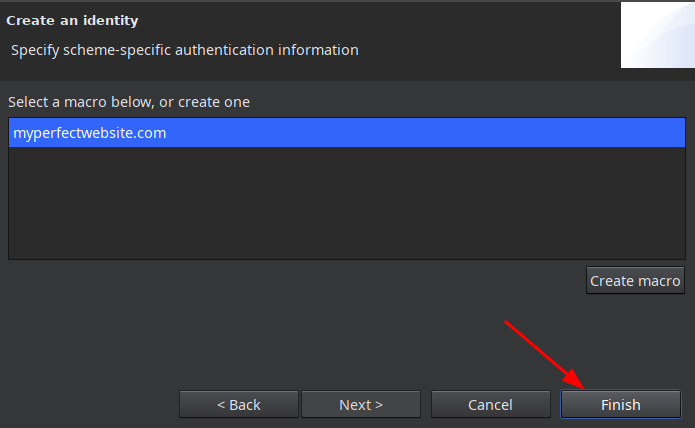
В окне увидим учетку для авторизации с добавленным только что макросом:
Создаем новое сканирование:
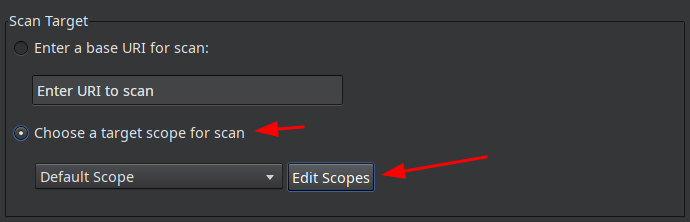
Некоторые части сайта могут быть недоступны из публичной части, их нужно добавить в сканирование. Также нужно исключить выход из учетки. Чтобы это учесть, то вместо ввода урла выбираем Choose a target scope for scan и жмем на кнопку Edit Scopes:
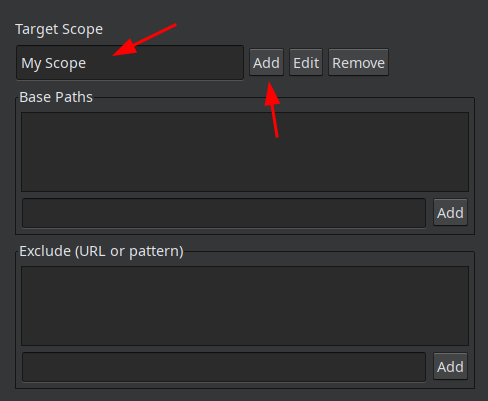
В открывшемся окне жмем на кнопку Add, вводим название и жмем enter:
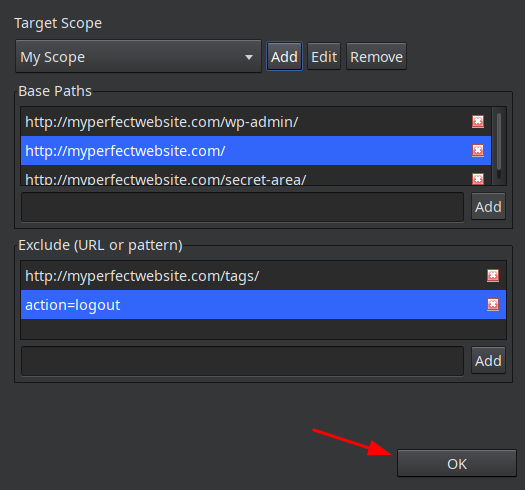
Далее в Base Paths забиваем базовые урлы, с которых будет начато сканирование (будут также проверятся все ссылки, которые сканер найдет на этой странице, т.е. сканер может поднятся выше указанных директорий), а в список Exclude нужно добавить ссылки (или паттерны), которые не нужно исключить (обязательно добавляем action=logout в исключения) и жмем OK:
Далее выбираем созданный список сканирования и жмем Next:
В следующем окне выбираем нужные модули и жмем Next:
Далее выбираем профиль и жмем Finish:
Ждем окончания сканирования.
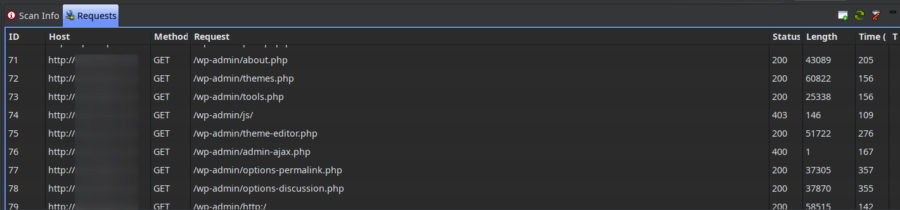
Чтобы убедиться в успешной авторизации, можно глянуть запросы. На скрине ниже как раз успешные запросы к страницам в админке:
Headless режим
Headless режим доступен при установке форка с гитхаба. Запуск осуществляется обычным скриптом на Python. Сам скрипт лежит в корне репозитория (example.py).
Копируем этот скрипт в любое место под любым именем:
cp /path/to/example.py /path/to/vega-headless.py
В скрипте нас интересуют следующие переменные:
target— урл для сканирования;result_path— путь к html отчету сканирования;vega_path— путь к бинарнику Vega.
Указываем нужные параметры и запускаем:
python3 /path/to/vega-headless.py
Скрипт процесс сканирования не отображает. После окончания результат будет сохранен в файл по пути, указанному в переменной result_path.
Применение headless режима вижу только в автоматизации сканирования. Теоретически можно расширить его функционал и сделать передачу переменных параметрами при запуске.
TL;DR
Сканер не гарантирует нахождение всех известных ему уязвимостей и не все найденные проблемы являются уязвимостями (каждую найденную проблему надо проверять). Но он отлично подходит для поверхностного автоматизированного сканирования.
Подробнее о функционале можно узнать в документации. Функционал сканера внушительный.
Все запуски сохраняются, и можно их просмотреть позже. Настройки окружения с отчетами хранятся в ~/.vega.
